챗GPT나 클로드 같은 강력한 클라우드 AI 서비스들이 일상을 지배하고 있지만, 마음 한구석에는 늘 찜찜함이 남아있습니다. "내가 입력한 이 소스코드나 민감한 개인 정보가 기업의 학습 데이터로 유출되진 않을까?", "매달 나가는 구독료가 은근히 아까운데..."라는 생각, 한 번쯤 해보셨을 겁니다. 만약 애플 실리콘(M시리즈) 맥북을 쓰고 계신다면 최고의 대안이 있습니다. 바로 **LM Studio**를 활용해 인터넷 연결 없이 100% 오프라인으로 돌아가는 '나만의 완전 프라이빗 AI'를 구축하는 것입니다. 터미널 명령어를 무서워하는 초보자도 마우스 클릭 몇 번으로 끝내는 로컬 LLM 구축 가이드를 공개합니다.
[핵심 요약 3줄 체크]
1. 압도적인 직관성: LM Studio는 복잡한 터미널 명령어(CLI) 대신, 마켓플레이스 형태의 세련된 GUI를 제공하여 오픈소스 AI 패치 과정이 매우 쉽습니다.
2. 애플 실리콘 최적화: M시리즈 칩셋의 핵심인 '통합 메모리(Unified Memory)'와 Metal 하드웨어 가속을 완벽하게 지원해 놀라운 토큰 연산 속도를 보여줍니다.
3. 철통 보안 하우스: 데이터가 바깥 인터넷망으로 단 1바이트도 유출되지 않으므로 사내 보안 문서 분석이나 비공개 블로그 초안 작성에 최적화되어 있습니다.
목차
- 1. 왜 맥북 유저들에게 'LM Studio'가 최고의 선택인가?
- 2. LM Studio 맥 버전 다운로드 및 환경 세팅 가이드
- 3. 내 맥북 사양에 맞는 맞춤형 AI 모델 검색 및 원클릭 다운로드
- 4. 실전 활용 1단계: Metal GPU 가속 켜고 첫 대화 나누기
- 5. 실전 활용 2단계: 프로 수준의 답변을 유도하는 시스템 프롬프트 세팅
- 6. 마치며: 인터넷이 끊겨도 든든한 나만의 로컬 지식 기지
1. 왜 맥북 유저들에게 'LM Studio'가 최고의 선택인가?
초보자 친화적인 원스톱 인터페이스
Ollama가 터미널 기반의 백엔드 강자라면, LM Studio는 독립적인 데스크톱 애플리케이션 형태를 취한 프론트엔드의 최강자입니다. AI 모델의 검색, 양자화 규격별 용량 확인, 다운로드, 그리고 실제 챗 인터페이스까지 프로그램 하나 안에서 전부 해결됩니다. 복잡한 가상환경(venv)을 세팅하거나 도커(Docker) 컨테이너를 올릴 필요가 전혀 없어 진입 장벽이 제로에 가깝습니다.
애플 실리콘 통합 메모리의 축복
애플의 M시리즈 칩셋은 CPU와 GPU가 램(RAM)을 공유하는 '통합 메모리 아키텍처'를 사용합니다. 일반 윈도우 PC는 고가의 그래픽카드 메모리(VRAM) 용량 한계 때문에 대형 AI 모델을 올리기 어렵지만, 맥북은 내 시스템 램 용량만큼 무겁고 똑똑한 AI 모델을 그대로 가속할 수 있습니다. LM Studio는 이 매커니즘을 영리하게 활용하여 클릭 한 번으로 맥북의 GPU 자원을 하이재킹해 폭발적인 추론 속도를 뿜어냅니다.

2. LM Studio 맥 버전 다운로드 및 환경 세팅 가이드
설치 과정은 일반 맥용 프로그램과 완전히 동일합니다. 군더더기 없이 깔끔하게 진행해 보겠습니다.
- 공식 사이트 방문: 맥북 웹 브라우저를 열고 LM Studio 공식 웹사이트에 접속합니다.
- 설치 파일 다운로드: 메인 화면에 있는 [Download LM Studio for Mac (M1/M2/M3/M4)] 버튼을 누릅니다. (인텔 맥북 유저라면 하단의 Intel 버전 링크를 선택해야 합니다.)
- 앱 폴더 이동: 다운로드된
.dmg파일을 더블 클릭하여 연 뒤, LM Studio 아이콘을 맥북의 [응용 프로그램(Applications)] 폴더로 드래그 앤 드롭합니다.
이제 런치패드에서 LM Studio를 실행하면 모든 기초 준비가 완료됩니다.
3. 내 맥북 사양에 맞는 맞춤형 AI 모델 검색 및 원클릭 다운로드
글로벌 리포지토리(HuggingFace) 다이렉트 검색
앱을 켜고 왼쪽 사이드바에서 돋보기(Search) 아이콘을 누르면, 전 세계 대형 AI 모델들이 상주하는 허깅페이스 저장소와 실시간으로 연동됩니다. 검색창에 원하는 모델의 이름을 치면 되는데, 특히 블로그 작성이나 매끄러운 한국어 문맥 처리를 원하신다면 **Qwen2.5**를 적극 추천합니다.
내 맥북 램(RAM) 사양별 최적의 모델 크기 선택
검색 결과 우측을 보면 Q4_K_M, Q8_0 같은 생소한 단어와 함께 파일 용량이 표시됩니다. 이는 AI 모델을 가볍게 압축한 '양자화(Quantization)' 규격입니다. 내 맥북 사양에 맞는 마지노선을 지켜야 튕김 없이 쾌적한 속도가 나옵니다.
| 맥북 메모리 (RAM) 사양 | 추천 모델 검색어 | 최적의 추천 파일 규격 | 한 끝 차이 엔지니어링 인사이트 |
|---|---|---|---|
| 기본형 (8GB RAM) | Qwen2.5-7B 또는 Phi-3 |
3B ~ 7B 체급 (Q4_K_M 규격) | 8GB 램에서는 시스템 점유율을 고려해 4GB 내외의 파일 크기가 가장 안전합니다. |
| 표준형 (16GB ~ 24GB) | Qwen2.5-14B |
14B 체급 (Q4_K_M 또는 Q5_K_M) | 블로그 작성 및 문맥 추론 퀄리티가 챗GPT 무료 버전 수준으로 튀어 오르는 구간입니다. |
| 고급형 (32GB / 64GB 이상) | Qwen2.5-32B 또는 Llama3.3 |
32B ~ 70B 대형 체급 (Q8_0 대형 규격) | 메모리 스왑 걱정 없이 딥한 프로그래밍 리팩토링이나 전문 보고서 집필이 가능합니다. |
원하는 모델을 골랐다면 우측의 [Download] 버튼을 누릅니다. 다운로드가 완료될 때까지 잠시 기다려 줍니다.

* 파일명: lm-studio-model-download.jpg
* ALT: LM Studio 검색창에서 Qwen2.5 14B 모델을 검색한 뒤 사양에 맞는 Q4_K_M 버전을 다운로드하는 마우스 클릭 동작
* 캡션: 모델 파일 우측에 내 기기에서 구동이 가능한지 녹색 불빛(Should fit in RAM)으로 친절하게 가이드해 줍니다.
4. 실전 활용 1단계: Metal GPU 가속 켜고 첫 대화 나누기
모델 로드 및 하드웨어 셋업
다운로드가 끝났다면 왼쪽 사이드바에서 말풍선(AI Chat) 아이콘을 눌러 본 대화방으로 이동합니다.
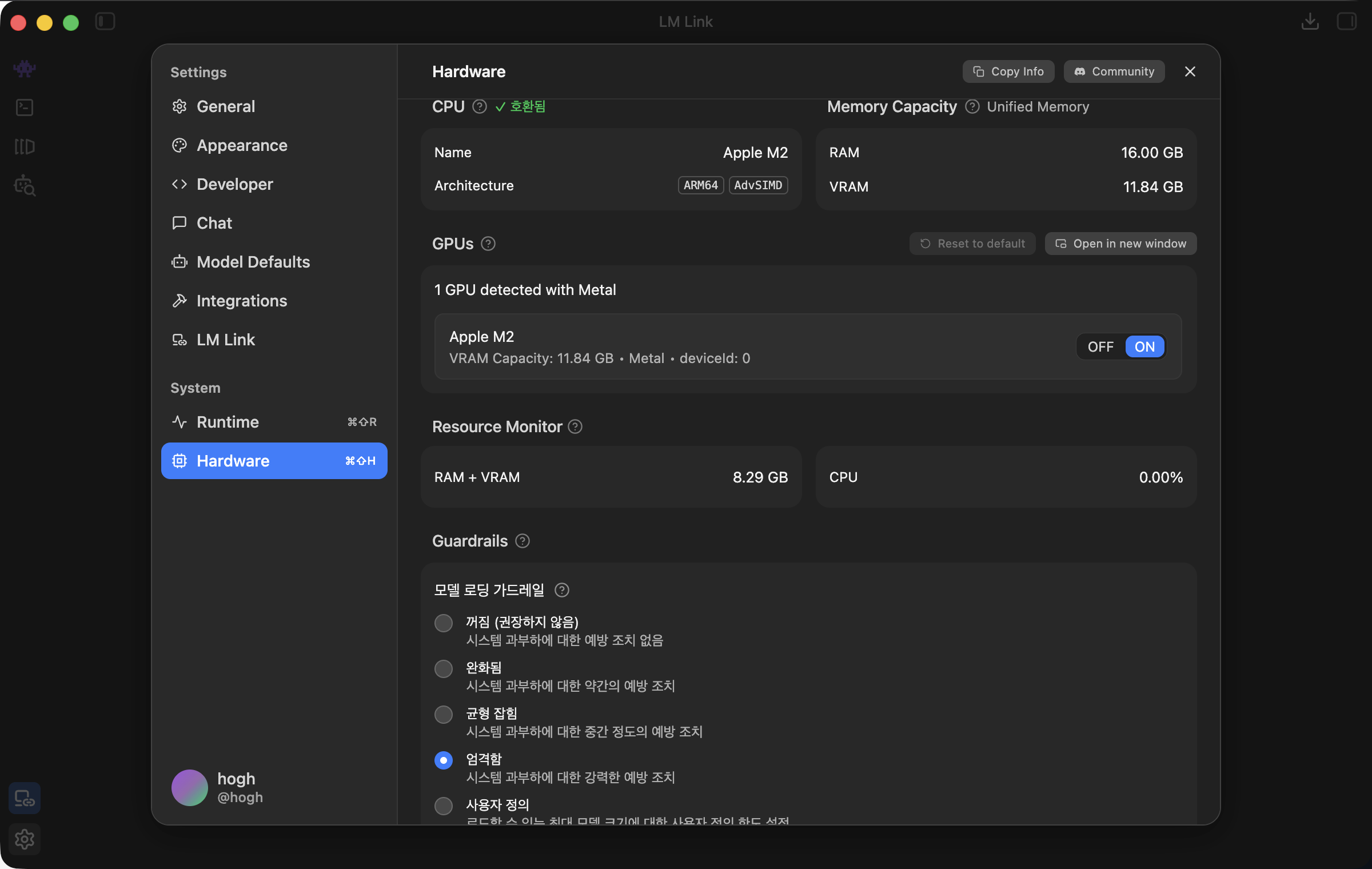
- 상단 중앙의
Select a model to load드롭다운을 눌러 방금 다운로드한 모델을 선택합니다. 맥북 메모리로 모델 데이터가 주입되기 시작합니다. - [치명적인 최적화 팁]: 우측 패널설정 창에서 [Hardware Settings] 메뉴를 펼친 뒤,
Hardware Acceleration항목을 기본 CPU에서Apple Metal혹은GPU가속으로 반드시 변경해 줍니다.
이 스위치를 켜야만 맥북의 강력한 GPU 코어가 깨어나면서 답변 텍스트가 기관총 쏘듯 실시간으로 뿜어져 나옵니다.
5. 실전 활용 2단계: 프로 수준의 답변을 유도하는 시스템 프롬프트 세팅
로컬 AI에게 프로 카피라이터의 페르소나 주입하기
처음 대화를 나눠보면 답변이 다소 심심하거나 완성도가 떨어질 수 있습니다. LM Studio 우측 패널의 **[System Prompt]** 영역에 아래의 구조화된 프롬프트 지시문을 복사해서 넣어보세요. 가벼운 로컬 모델의 뇌세포를 정교하게 타겟팅하여 방문자의 체류시간을 늘려주는 완성도 높은 블로그 글을 찍어내기 시작합니다.
[블로그 에디터 최적화 시스템 프롬프트]
"너는 최신 검색엔진 최적화(SEO) 표준에 맞춰 정교한 마크다운 서식으로 글을 작성하는 프로 블로그 카피라이터이다. 사용자가 키워드나 주제를 던지면 가독성이 뛰어난 정보성 포스팅을 완성하라. 모든 글은 다음 규칙을 따른다:
1. 무조건적인 텍스트 나열은 금지하며, 독자가 3초 만에 정보를 스캔할 수 있도록 HTML 소제목(<h2>, <h3>)과 표(Table), 인용 블록을 적극 구사할 것.
2. 딱딱한 설명문 어조를 지양하고, 읽기 편한 구어체 표현(~해보셨나요?, ~방법을 정리해 드립니다)을 사용할 것.
3. 핵심 개념 뒤에는 누구나 공감할 수 있는 일상적인 비유나 비하인드 인사이트를 최소 하나 이상 결합할 것."

6. 마치며: 인터넷이 끊겨도 든든한 나만의 로컬 지식 기지
지금까지 LM Studio를 활용해 맥북 내부에 독립적인 고지능 AI 허브를 구축하는 핵심 파이프라인을 짚어보았습니다. 오픈소스 모델 진영의 폭발적인 발전 덕분에, 이제는 값비싼 월 구독료를 내지 않고도 기업 보안 규정을 완벽히 준수하면서 나만의 데이터 자산을 다듬어줄 프라이빗 파트너를 맥북 안에 영구 소장할 수 있게 된 것이죠. 오늘 소개해 드린 램 사양별 모델 매칭 룰과 Metal GPU 가속 세팅을 기반으로, 똑똑하고 안전한 로컬 AI 인프라를 직접 경험해 보시길 바랍니다!
다양한 오픈소스 모델들의 정밀한 아키텍처 비교 데이터나, 내 로컬 가속 포트를 외부 서드파티 웹 플러그인과 연동하는 개발자용 API 로컬 호스트(`localhost:1234`) 엔드포인트 명세서가 필요하시다면 LM Studio 공식 개발자 문서 플랫폼 Docs를 참고하시는 것을 적극 권장합니다.
팬리스 기기인 맥북에어 특성상 장시간 대형 추론 연산을 지속하면 하판 발열로 인한 스로틀링이 올 수 있습니다. 장문의 롱폼 블로그 포스팅을 여러 개 연달아 뽑아내실 때는 알루미늄 거치대를 활용해 기기 냉각을 도와주세요.
본 포스팅은 순수한 기술 정보 전달 및 오픈소스 가속화 분석을 목적으로 작성되었으며, 각 오픈소스 모델 파일의 크리에이티브 커먼즈 라이선스(상업적 이용 한계 규정 등)를 반드시 확인하고 준수하여 안전하게 가동하시기 바랍니다.
💬 여러분의 로컬 AI 구축 후기를 공유해 주세요!
1. 사용 중이신 맥북 사양(예: M2 16GB / M3 8GB)에서 Qwen 2.5 14B 모델의 로딩 시간과 첫 문장 타이핑 속도는 만족스러우신가요?
2. 모델 다운로드 도중 Network Error가 나거나 Metal 가속 체크박스를 켰을 때 화면이 크래시(강제 종료)되는 구간이 있다면 댓글로 편하게 질문을 남겨주세요!